Hoe kunt u uw Flickr-zoekslagen verder automatiseren?
In deel 1 van deze blogpost hebben wij u laten zien hoe u gebruikers op Flickr kunt vinden aan de hand van een e-mailadres. Wij hebben u laten zien dat u hiervoor de publieke API-sleutel van Flickr kunt gebruiken. In deel 2 van deze blogpost hebben wij beschreven hoe u zelf een Python-script kunt maken om uw zoekslagen te automatiseren. In deze blogpost leggen wij u uit hoe u uw resultaten kunt opschonen, hoe u uw script meer gebruikersvriendelijk kan maken en hoe u uw resultaten kunt opslaan in een CSV-bestand.
Allereerst: gebruik een nieuwe API-sleutel
Om de publieke API van Flickr te kunnen gebruiken heeft u, zoals u inmiddels weet, de publieke API key van Flickr nodig. Zoek deze publieke API key bijvoorbeeld op via de Flickr Api Explorer: typ handmatig een e-mailadres als “johndoe@ gmail.com” in en bekijk de URL onderin het scherm. In ons geval leidt dit tot de onderstaande werkende URL. De API key uit deze URL kunt u vervolgens gebruiken in uw eigen Pythonscript. Bent u vergeten hoe dit moet? Lees dan deel 2 van deze blogpost even terug.
https://www.flickr.com/services/rest/?method=flickr.people.findByEmail&api_key=3eeb03cea945a8f597c529ebd454051b&find_email=johndoe%40gmail.com&format=rest
Uw Python script opschonen
Als u alle stappen uit onze tweede blog heeft gevolgd en u zojuist een nieuwe publieke API key in uw Python-script heeft verwerkt, dan kunt u aan de hand van uw script controleren of er een gebruiker is gekoppeld aan een door u opgegeven e-mailadres. Voordat u verder gaat is het handig om dit even te testen. Werkt alles? Lees dan verder.
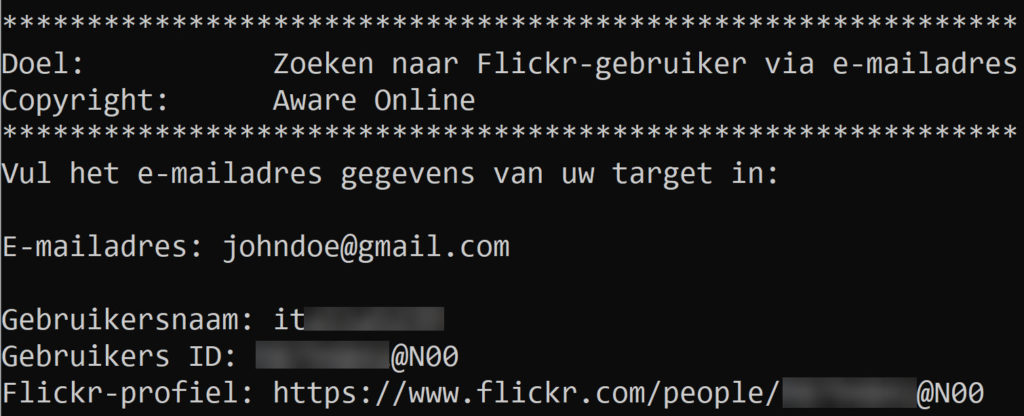
Stap 1: bekijk het resultaat van uw script
Als u het resultaat van uw script bekijkt, dan kunnen we het resultaat gebruiken om na te denken over hoe we uw script kunnen verbeteren om niet-relevante informatie weg te filteren. In onderstaande resultaten ziet u bijvoorbeeld een “response code” met de waarde “200″ staan. Ondanks dat dit resultaat aangeeft dat uw request richting de webserver is geslaagd, heeft deze informatie verder geen waarde als we enkel willen weten of er een gebruiker aan een e-mailadres gekoppeld is. We gaan ons script dus zodanig opschonen dat u enkel de “user id” en de “username” terug krijgt.
Stap 2: installeer de Python-bibliotheek BeautifulSoup
Voordat we uw script opschonen installeren we de Python library “BeautifulSoup“. Met de Python-bibliotheek BeautifulSoup kunt u data uit een HTML- of een XML-bestand ophalen en op een dusdanige wijze presenteren dat Python-objecten gemakkelijk te doorlopen zijn. Installeer de bibliotheek als volgt via uw Windows Command Prompt (CMD):
pip install beautifulsoup4
Stap 3: imporeer de Python-bibliotheek BeautifulSoup
Importeer de BeautifulSoup-bibliotheek door het volgende in uw Python-script op te nemen:
from bs4 import BeautifulSoup
U ziet in het bovenstaande commando de tekst “from bs4 import” staan. Dit gedeelte geeft aan dat u enkel het object “BeautifulSoup” uit de “BeautifulSoup-bibliotheek” importeert.
Stap 4: installeer de lxml-parser
BeautifulSoup kunt u gebruiken met “parsers” als de “html.parser” en de “lxml-parser“. Parsers “parseren” rommelige of verkeerd geformatteerde HTML-code waardoor uw resultaten er meer gestructureerd uit komen te zien. Klinkt dit een beetje vaag? Dan zal verderop wel duidelijk worden wat we precies bedoelen. Installeer lxml als volgt via de Windows Opdracht Prompt (CMD)
pip install lxml
Stap 5: importeer de lxml-parser
Importeer de lxml-parser als volgt in uw Python-script.
import lxml
Stap 6: maak een Soup-object aan
Om BeautifulSoup uit te voeren, gebruikt u het onderstaande commando.
#soup maken
soup = BeautifulSoup(response.text, 'lxml')
In het bovenstaande vormt het eerste gedeelte “response.text” de HTML-tekst waarop het object “soup” is gebaseerd. De “response.text” was immers het resultaat van de opgevraagde HTML-pagina zoals we deze eerder hebben gespecificeerd. Het tweede gedeelte “lxml” geeft de parser aan die BeautifulSoup moet gebruiken om het object “soup” aan te maken.
Stap 7: print het Soup-object
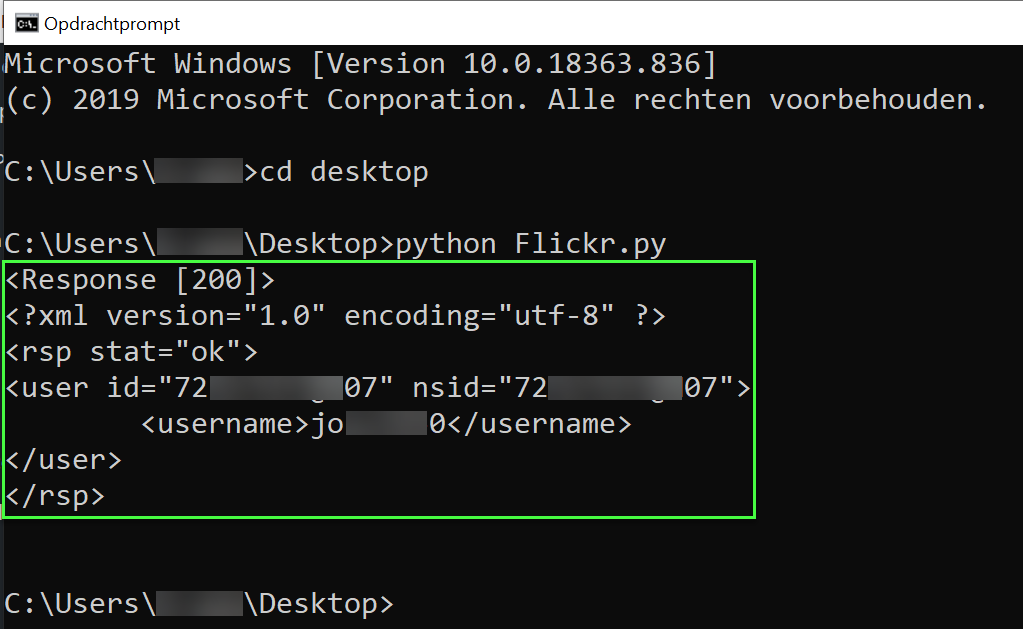
Om te testen of alles werkt kunt u nu uw script uitvoeren. Ons script ziet er op dit moment als volgt uit.

En geeft het volgende resultaat:

Dit script werkt dus. En als u goed kijkt ziet u nu dat het resultaat er iets anders uitziet dan het eerdere resultaat. U ziet nu bijvoorbeeld ook de gedeeltes “<html><body>” en “</body></html>” staan. Dit is heel logisch, want u heeft immers de HTML-inhoud van een webpagina opgevraagd.
Stap 8: gebruik “prettyprint” voor mooiere resultaten
Om uw resultaten mooier (in een “geneste structuur“) te weergeven, kunt u het onderstaande commando gebruiken.De
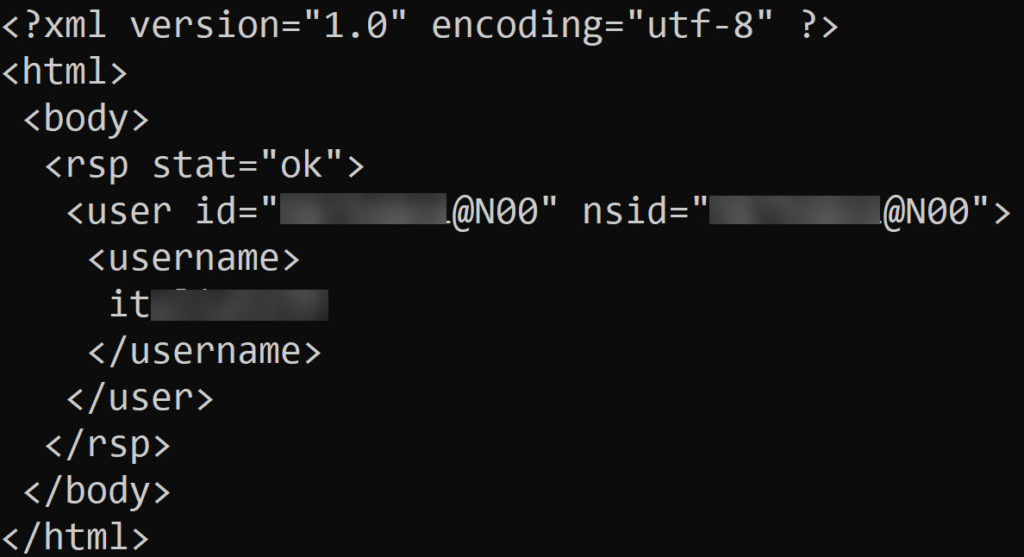
print(soup.prettify())
U krijgt hiermee het volgende resultaat waarin de HTML-structuur genest wordt weergegeven. Dat wil bijvoorbeeld zeggen dat “<rsp stat=”ok”>” tot aan “</rsp>” onder de “<body>” van de HTML-pagina vallen.
Stap 9: de print-resultaten filteren
Met bovenstaande bent u er nog niet, u wilt immers enkel de user-id en de username van de betreffende gebruiker uitprinten. Hiervoor moet u in de HTML kijken naar waar de informatie die u zoekt precies staat opgeslagen. Als we beginnen met de gebruikersnaam, dan wordt de gebruikersnaam bijvoorbeeld direct getoond tussen “<username>” en “</username>“. U kunt vervolgens precies dit stukje in uw script aanwijzen via het onderstaande commando.
#filteren van resultaten
user_name = soup.username.text
Met het bovenstaande commando zoekt u naar het text-gedeelte dat zich bevindt in de volgende structuur: html > body > username. Door “soup.username.text” te gebruiken roept u direct de waarde van het object “username” aan, welke in dit geval de gebruikersnaam betreft. Wilt u de variabele “user_name” uitprinten, dan doet u dat als volgt:
print(user_name)
Het resultaat dat u te zien krijgt is dan enkel de username:

Stap 9: zelf tekst bijvoegen
Uw script doet nu precies hetgeen wat het zou moeten doen: het toont de gebruikersnaam van een gebruiker op basis van een e-mailadres dat u heeft opgegeven. U kunt met het onderstaande commando duidelijker maken wat het resultaat is dat u te zien krijgt. U kunt dus zelf begeleidende tekst opgeven.
print('\nGebruikersnaam:',user_name)
Het resultaat is dan als volgt:

Stap 10: meer filters gebruiken en deze uitprinten
Met bovenstaande heeft u enkel de gebruikersnaam uitgeprint, maar u wilt ook nog het user-id weten. U kunt daarvoor onderstaande code gebruiken.
#filteren van resultaten
user_name = soup.username.text
user_id = soup.user
user_profiel = ('https://www.flickr.com/people/'+user_id.get('id'))
#alles printen
print('\nGebruikersnaam:', user_name)
print('Gebruikers ID:', user_id.get('id'))
print('Flickr-profiel:', user_profiel)
Indien u vervolgens alles uitprint, krijgt u het onderstaande resultaat.

Uw script gebruiksvriendelijk maken
Bovenstaande script werkt, maar is nog niet heel gebruiksvriendelijk. U moet namelijk steeds de code van uw script aanpassen om deze te laten werken, en dat moet u ook nog eens voor elk e-mailadres doen dat u wilt controleren. Het is dus tijd om uw script meer gebruiksvriendelijk te maken.
Stap 1: maak een mooie template
Veel scripts hebben in het begin een mooie template. Een script ziet er daardoor veel spannender uit. U zou dit al heel simpel als volgt kunnen doen.
print()
print('\n*************************************************************************************'
'\nDoel: \t\tZoeken naar Flickr-gebruiker via e-mailadres'
'\nCopyright: \tAware Online')
print('*************************************************************************************')
Als u het script nu print, krijgt u namelijk het volgende resultaat. Is dat niet tof?

Stap 2: maak nieuwe input-variabelen aan
Het script dat u gemaakt heeft is op dit moment nog vrij statisch. In het script zit namelijk de API key van Flickr verwerkt en ook het e-mailadres dat u wilt onderzoeken. Indien u het script vaker wilt gebruiken, kunt u wellicht de API key en het e-mailadres als input-waarde gebruiken om in een variabele op te slaan.
Voor het e-mailadres kunt u dat als volgt doen, de API key laten we voor nu gewoon staan:
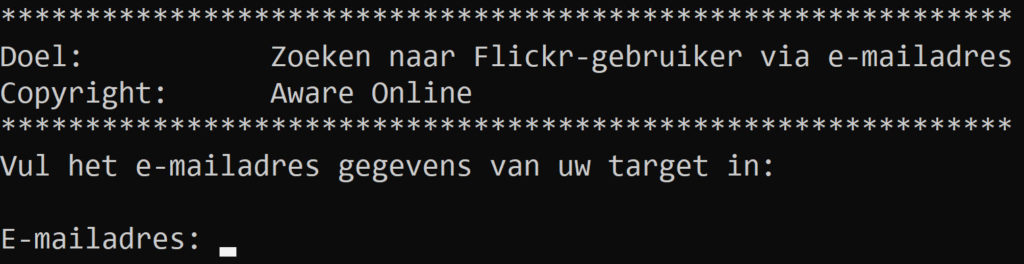
print('Vul het e-mailadres gegevens van uw target in:\n')
emailadres = input("E-mailadres: ")
Let erop dat u in het bovenstaande geval ook de URL in uw code aanpast. Het e-mailadres dat u via het input-veld opgeeft wilt u immers gebruiken in de URL die u gaat bezoeken. Dat kan bijvoorbeeld als volgt.
url = 'https://www.flickr.com/services/rest/?method=flickr.people.findByEmail&api_key=3eeb03cea945a8f597c529ebd454051b&find_email='+emailadres+'&format=rest'
Als u nu het resultaat print, wordt aan u gevraagd om een e-mailadres van uw target in te vullen. Dit kunt u handmatig doen, waarna het script gewoon wordt uitgevoerd als voorheen.
De resultaten opslaan in een CSV-bestand
Met uw script kunt u controleren of er een e-mailadres aan een account op Flickr gekoppeld is. Door uw script te runnen krijgt u uw resultaten in uw terminal te zien. Soms is het handiger om de gevonden resultaten direct op te slaan in een bestand waarmee u verder kunt werken. In een CSV-bestand bijvoorbeeld. Hieronder leest u hoe u uw resultaten opslaat in een CSV-bestand.
Stap 1: installeren xlwt-library
Om spreadsheets te kunnen genereren die gebruikt kunnen worden in Microsoft Excel is een Python-bibliotheek als “xlwt” nodig. Deze Python-bibliotheek kunt u als volgt installeren via de Windows Command Prompt (CMD):
pip install xlwt
Stap 2: importeren workbook uit xlwt
Uit de Python-bibliotheek xlwt hebben we vervolgens het object “workbook” nodig. Dit object importeert u als volgt.
#importeren workbook uit xlwt-library
from xlwt import workbook
Stap 3: workbook aanmaken
Met de Python-bibliotheek kunt u vervolgens als volgt een workbook als variabele “wb” aanmaken.
#aanmaken van een workbook
wb = Workbook()
Stap 4: spreadsheet aanmaken
Nu u een workbook heeft aangemaakt, kunt u een spreadsheet aan te maken. Dat doet u als volgt:
#Aanmaken van een sheet via add_sheet
sheet1 = wb.add_sheet('Sheet 1')
Met deze functie heeft u een spreadsheet aangemaakt en heeft u deze spreadsheet de naam “Sheet 1” gegeven.
Stap 5: spreadsheet vullen
Nu u een spreadsheet heeft aangemaakt, kunt u specificeren wat er op de spreadsheet geschreven moet worden. Dat doet u als volgt:
#Sheet vullen
sheet1.write(0, 0, 'E-mailadres')
sheet1.write(0, 1, 'Username')
sheet1.write(0, 2, 'User ID')
sheet1.write(0, 3, 'Link')
De waardes voor de komma geven aan in welke “cel” op het spreadsheet u zich bevindt. De waarde “0,0” geeft dus aan dat u zich in cel “A1” bevindt. Wilt u cel “B1” selecteren, dan schuift u dus als het ware één plaatsje op naar rechts. In uw code schrijft u dan “0,1,“. De waarde die u vervolgens tussen quotes ‘E-mailadres1‘ weergeeft, geven aan wat er in de cel komt te staan. In dit voorbeeld heeft cel “A1” dus de waarde “E-mailadres“. Met onderstaande code kunt u vervolgens de waardes invullen op basis van wat uw script heeft gegenereerd.
sheet1.write(1, 0, emailadres)
sheet1.write(1, 1, user_name)
sheet1.write(1, 2, user_id.get('id'))
sheet1.write(1, 3, user_profiel)
Stap 6: document opslaan
Voordat u uw script runt, moet u bovenstaande uitwerkingen nog opslaan in een bestand. Dat doet u als volgt, met in dit geval als naam “flickr_resultaat.xls“:
#bestand opslaan
wb.save('flickr_resultaat.xls')
Het eindresultaat ziet er dan als volgt uit.

Wat nu verder?
Met bovenstaande stappen heeft u een basaal Python-script gemaakt waarmee u kunt controleren of er een gebruiker op Flickr aan één specifiek e-mailadres is gekoppeld. U heeft uw resultaten opgeschoond, u heeft uw script gebruiksvriendelijker gemaakt en u heeft uw resultaten opgeslagen in een CSV-bestand. In een volgende blogpost leggen wij u uit hoe u de informatie van een specifiek profiel kunt scrapen, en hoe u meerdere e-mailadressen kunt importeren en verwerken. Heeft u tips of suggesties? Laat het ons weten!
1 Comment