How to further automate your Flickr searches?
First of all: use a new API key
To use Flickr’s public API, as you know by now, you need Flickr’s public API key. Find this public API key via the Flickr Api Explorer: manually enter an email address such as “johndoe@gmail.com” and view the URL at the bottom of the screen. In our case, this leads to the working URL below. You can then use the API key from this URL in your own Python script. Have you forgotten how to do this? Then read part 2 of this blog post over again.
https://www.flickr.com/services/rest/?method=flickr.people.findByEmail&api_key=3eeb03cea945a8f597c529ebd454051b&find_email=johndoe%40gmail.com&format=rest
Cleaning your Python script
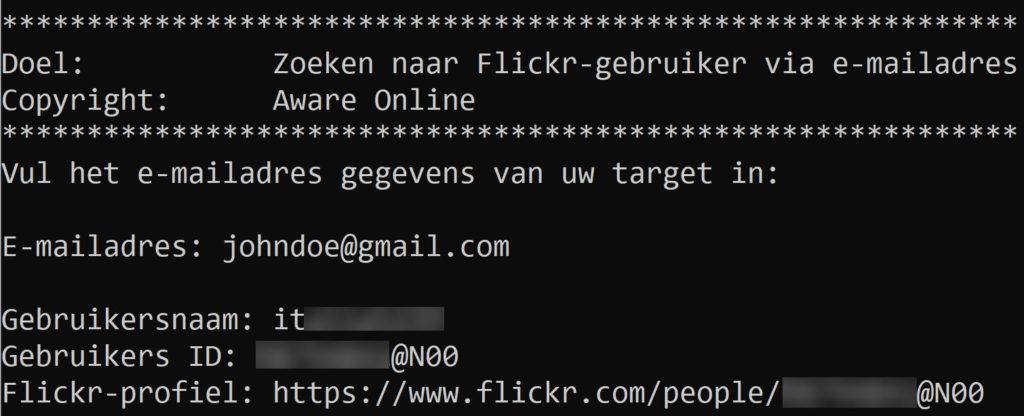
Step 1: check the result of your script
Step 2: install the Python library BeautifulSoup
pip install beautifulsoup4
Step 3: import the Python library BeautifulSoup
from bs4 import BeautifulSoup
You will see the text “from bs4 import” in the above command. This section indicates that you only import the object “BeautifulSoup” from the “BeautifulSoup library“.
Step 4: install the lxml-parser
pip install lxml
Step 5: import the lxml-parser
Import the lxml-parser into your Python script as follows:
import lxml
Step 6: create a Soup object
To run BeautifulSoup, use the command below.
#create soup
soup = BeautifulSoup(response.text, 'lxml')
In the code above, the first part “response.text” is the HTML text on which the object “soup” is based. After all, the “response.text” was the result of the requested HTML page as we specified earlier. The second part “lxml” specifies the parser BeautifulSoup should use to create the object “soup“.
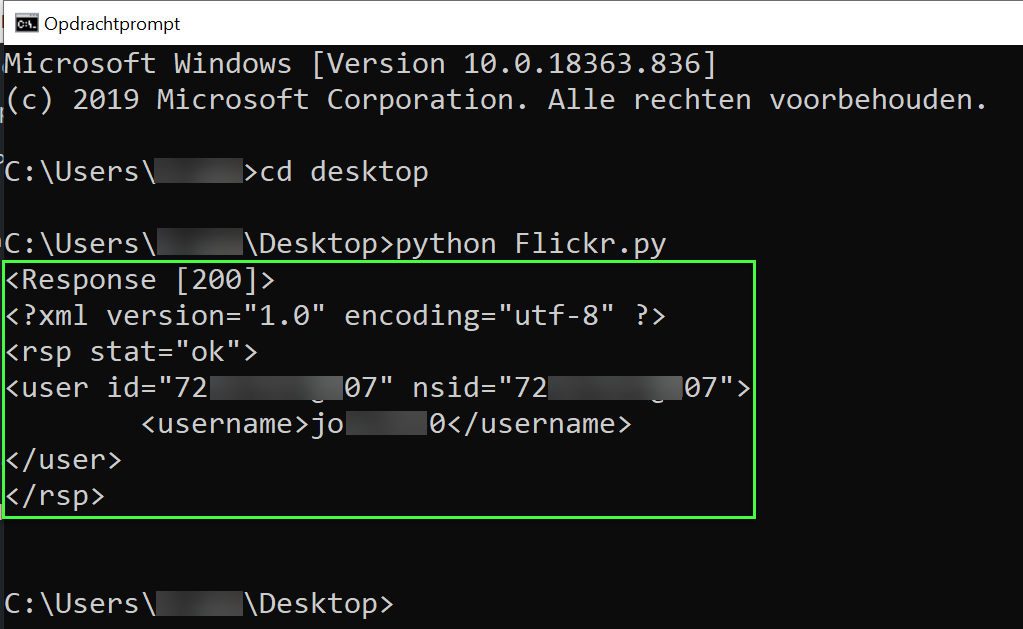
Step 7: print the Soup object
To test if everything works fine you can now run your script. Our script currently looks like this.


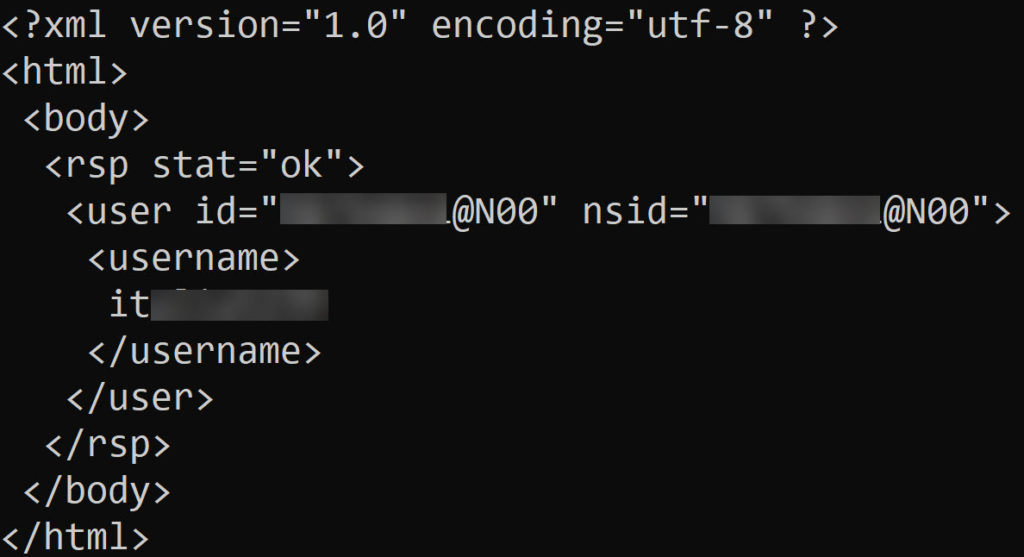
Step 8: use “prettyprint” for nicer results
print(soup.prettify())
Step 9: filtering the print results
With the code above you are not there yet, after all you just want to print out the user ID and username of your targeted user. For this you need to look in the HTML where exactly the information you are looking for is stored. For example, if we start with the username, the username is immediately shown between “<username>” and “</username>“. You can then point to exactly this part in your script using the command below.
#filter results
user_name = soup.username.text
print(user_name)
The result you will see is only the username:

Step 9: add text to your results
print('\nUsername:',user_name)
The result will look like the following:

Step 10: adding multiple filters and printing the results
#filter results
user_name = soup.username.text
user_id = soup.user
user_profiel = ('https://www.flickr.com/people/'+user_id.get('id'))
#print results
print('\nUsername', user_name)
print('User ID:', user_id.get('id'))
print('Flickr-profile:', user_profiel)

Making your Python script user-friendly
Step 1: create your own fancy template
print()
print('\n*************************************************************************************'
'\nPurpose: \t\tFind Flickr profiles by email'
'\nCopyright: \tYour Name here')
print('*************************************************************************************')

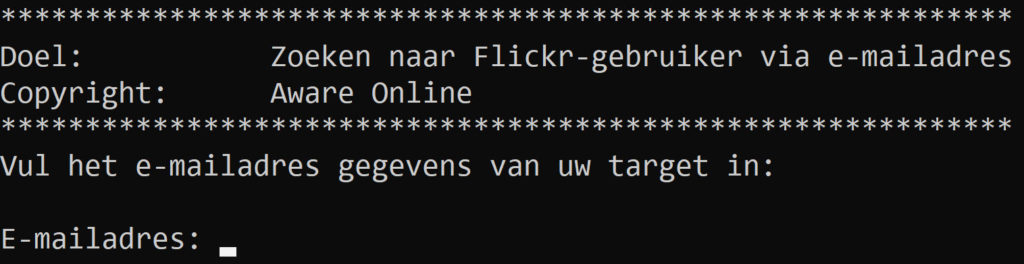
Step 2: create new input variables
print('Fill in target email:\n')
emailadres = input("Email addddres: ")
Please note that you will also need to edit the URL in your code. After all, you want to use the email address you enter via the input field in the URL you are going to visit. This can be done as follows.
url = 'https://www.flickr.com/services/rest/?method=flickr.people.findByEmail&api_key=3eeb03cea945a8f597c529ebd454051b&find_email='+emailadres+'&format=rest'
Save the results to a CSV file
Step 1: install the xlwt library
pip install xlwt
Step 2: import workbook from xlwt
From the Python library xlwt we need the object “workbook“. You can import this object as follows.
#import workbook from xlwt library
from xlwt import workbook
Step 3: create a workbook
Using the Python library, you can create a workbook as variable “wb” as follows:
#create workbook
wb = Workbook()
Step 4: create a spreadsheet
#Create a sheet via add_sheet
sheet1 = wb.add_sheet('Sheet 1')
Step 5: fill the spreadsheet with your data
Now that you have created a spreadsheet, you can specify what should be written on the spreadsheet. You can do this as follows:
#Fill in spreadsheet
sheet1.write(0, 0, 'Email address')
sheet1.write(0, 1, 'Username')
sheet1.write(0, 2, 'User ID')
sheet1.write(0, 3, 'Link')
sheet1.write(1, 0, emailadres)
sheet1.write(1, 1, user_name)
sheet1.write(1, 2, user_id.get('id'))
sheet1.write(1, 3, user_profiel)
Step 6: save the document
#save document
wb.save('flickr_resul.xls')
The end result looks like this.
